正则表达式就是描述字符串排列的一套规则。
基础知识
原子
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子,常见的原子有以下几类:
- 普通字符
- 非打印字符
- 通用字符
- 原子表
普通字符
可以使用一些普通的字符,比如数字、大小写字母、下划线等都可以作为原子使用。
1 | import re |
非打印字符
所谓的非打印字符,指的是一些在字符串中用于格式控制的符号,比如换行符等。
1 | import re |
通用字符
所谓的通用字符,即一个原子可以匹配一类字符。
1 | import re |
原子表
使用原子表,可以定义一组地位平等的原子,然后匹配的时候会取该原子表中的任意一个原子进行匹配,在Python中,原子表由[]表示。类似的,[^]代表的是除了中括号里面的原子均可以匹配。
1 | import re |
元字符
所谓的元字符,就是正则表达式中具有一些特殊含义的字符。具体来说,元字符可以分为:任意匹配元字符、边界限制元字符、限定符、模式选择符、模式单元等。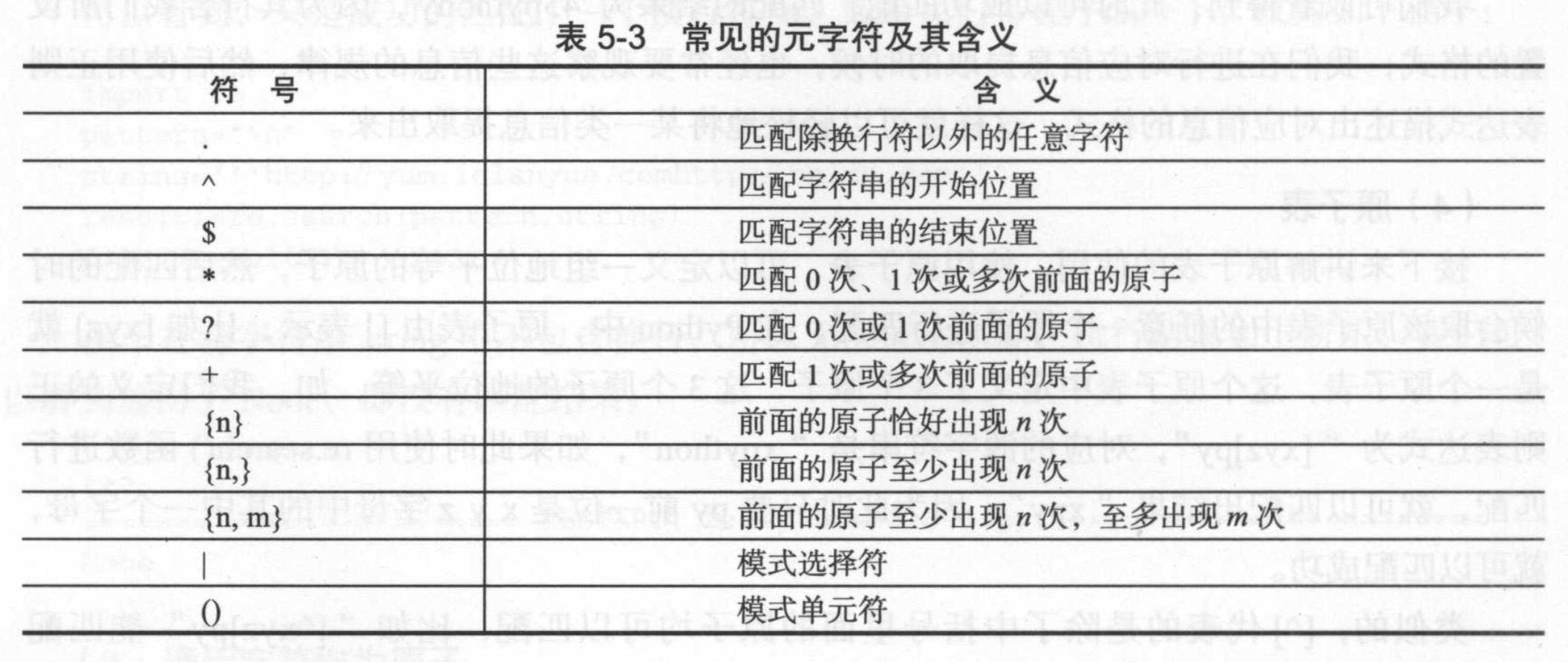
任意匹配元字符
可以使用”.”匹配一个除换行符以外的任意字符。
1 | import re |
边界限制元字符
可以使用”^”匹配字符串的开始,使用”$”匹配字符串的结束。
1 | import re |
限定符
常见的限定符包括*、?、+、{n}、{n,}、{n, m}。
1 | import re |
模式选择符
使用模式选择符,可以设置多个模式,匹配时,可以从中选择任意一个模式匹配。
1 | import re |
模式单元
可以使用”()”将一些原子组合成一个大原子使用,小括号括起来的部分会被当做一个整体去使用。
1 | import re |
模式修正
所谓模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。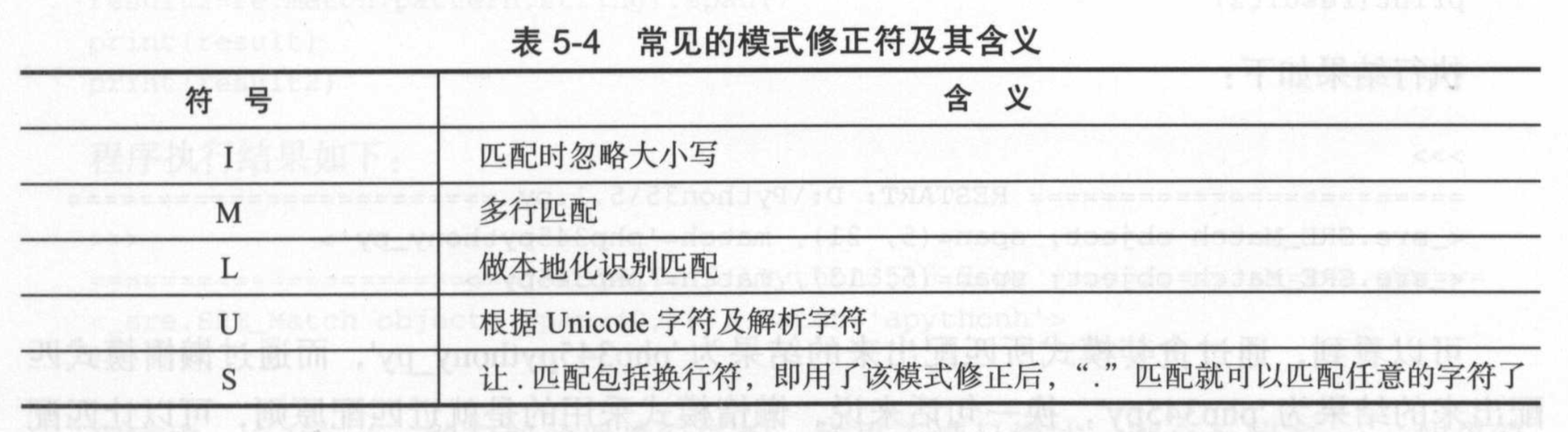
1 | import re |
贪婪模式与懒惰模式
在某些字符间匹配任意字符,贪婪模式的核心点就是尽可能多地匹配,而懒惰模式的核心点就是尽可能少地匹配。
1 | import re |
常见函数
re.match()函数
如果想要从源字符串的起始位置匹配一个模式,可以使用re.match()函数,使用格式是:
re.match(pattern, string, flag)
第一个参数代表对应的正确表达式,第二个参数代表对应的源字符,第三个参数是可选参数,代表对应的标志位,可以放模式修正符等信息。
1 | import re |
re.search()函数
使用该函数进行匹配,会扫描整个字符串并进行对应的匹配。
1 | import re |
全局匹配函数
将符合模式的内容全部都匹配出来。思路如下:
- 使用re.compile()对正则表达式进行预编译。
- 编译后,使用findall()根据正则表达式从源字符串中将匹配的结果全部找出。
1 | import re |
re.sub()函数
如果想根据正则表达式来实现替换某些字符串的功能,可以使用re.sub()韩式实现。
re.sub(pattern, rep, string, max)
其中,第一个参数为对应的正则表达式,第二个参数为要替换成的字符串,第三个参数为源字符串,第四个参数为可选项,代表最多替换的次数,如果忽略不写,则会将符合模式的结果全部替换。
1 | import re |
常见实例解析
匹配.com或.cn后缀的URL网址
将一串字符串里面以.com或.cn为域名后缀的URL网址匹配出来,过滤掉其他的无关信息。
1 | import re |
匹配电话号码
将一串字符串里面出现的电话号码信息提取出来,过滤掉其他无关信息。
1 | import re |
匹配电子邮件地址
将一串字符串里面出现的电子邮件信息提取出来,过滤掉其他无关信息。
1 | import re |