pyspider的架构主要分为Scheduler(调度器)、Fetcher(抓取器)、Processer(处理器)三个部分,整个爬取过程受到Monitor(监控器)的监控,抓取的结果被Result Worker(结果处理器)处理.
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processer负责解析网页内容,然后将新生成的Request发给Scheduler进行调度,将生成的提取结果输出保存。
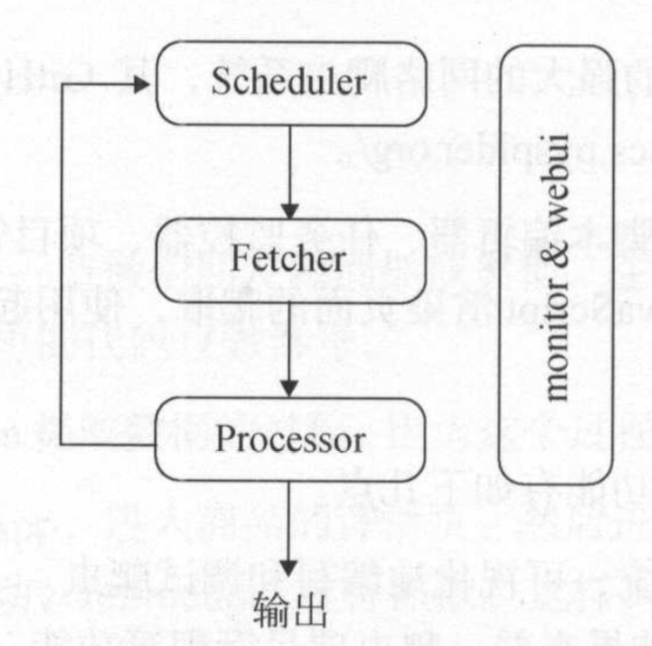
pyspider的任务执行流程的逻辑很清晰,具体过程如下所示。
- 每个pyspider的项目对应一个Python脚本,该脚本中定义了一个Handler类,它有一个on_start()方法。爬取首先调用on_start()方法生成最初的抓取任务,然后发送给 Scheduler进行调度。
- Scheduler将抓取任务分发给Fetcher进行抓取,Fetcher执行并得到响应,随后将响应发送给Processer。
- Processer处理响应并提取出新的URL生成新的抓取任务,然后通过消息队列的方式通知Scheduler当前抓取任务执行情况,并将新生成的抓取任务发送给Scheduler。如果生成了新的提取结果,则将其发送到结果队列等待Result Worker处理。
- Scheduler接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回Fetcher进行抓取。
- 不断重复以上工作,直到所有的任务都执行完毕,抓取结束。
- 抓取结束后,程序会回调on_finished()方法,这里可以定义后处理过程。